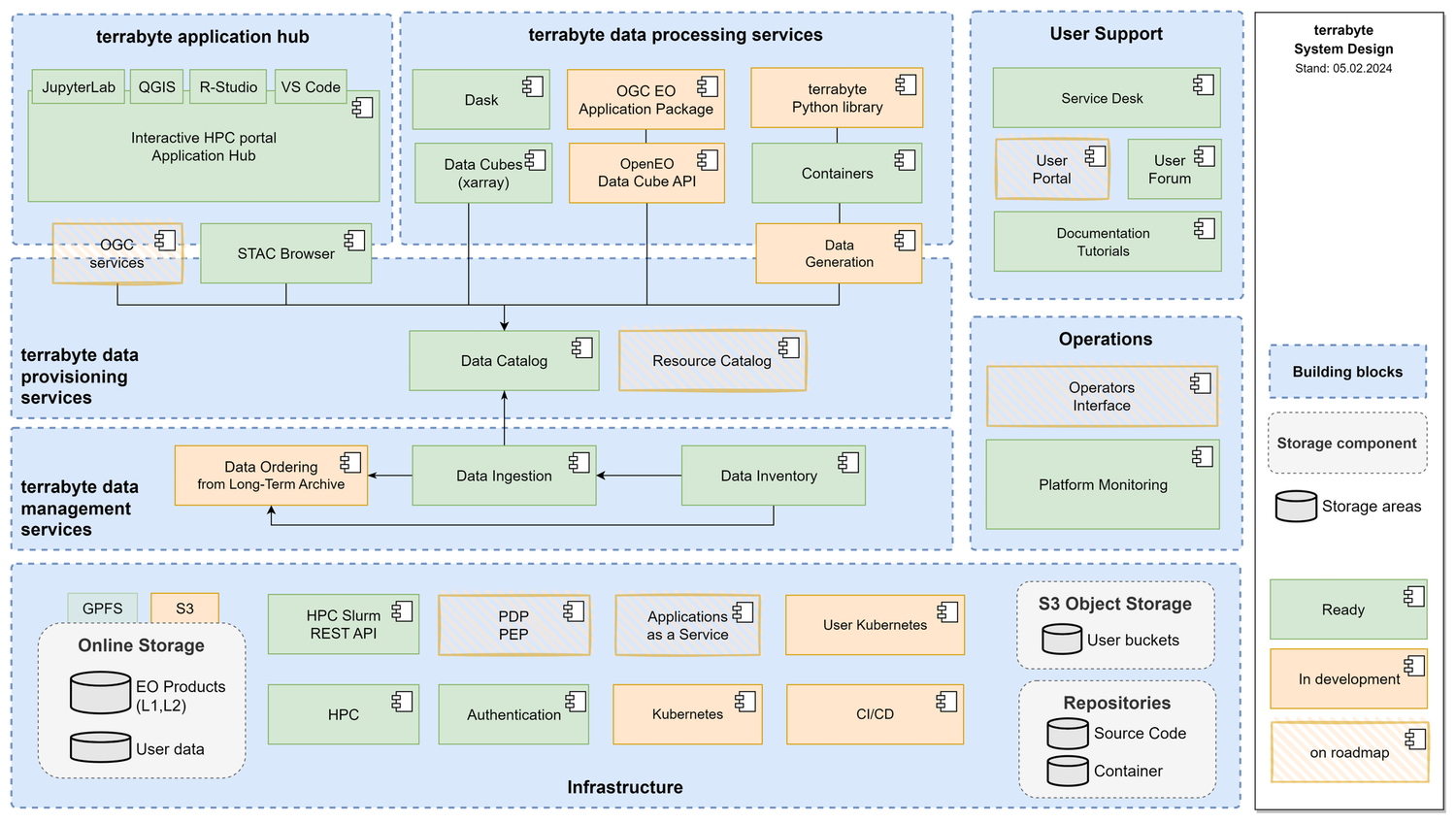
Building Blocks
The system is split into the following building blocks: Infrastructure, Operations, User Support, Data Management Services, Data Provisioning Services, Data Processing Services, and Application Hub. The design includes components that are ready (green), in development (yellow), and components that are on the roadmap.
The infrastructure of terrabyte combines High Performance Computing (HPC) with on-premise Kubernetes-based cloud services. The 50 Petabyte of online storage is available via a GPFS file system mounted on all compute (HPC) and services (Kubernetes) nodes. Currently, an S3-compatible interface is being integrated. In addition, S3-compatible object storage is available for the use in the cloud services. For operations, a monitoring stack based on Telegraf, InfluxDB, Prometheus, and Grafana is available. An interface for operators to configure services and deployments is on the roadmap. For supporting users, a support forum for exchange amongst users and questions & answers as well as a JIRA-based service desk are available. Tutorials and best practices with example Jupyter Notebooks are provided on GitHub.
The terrabyte data management services include a Camunda-based workflow engine for data ingestion and curation. A data inventory based on STAC is regularly updated with historical and new EO data. The inventory service can be used from the ingestion service to order data, which are not yet available on the platform.
The terrabyte data provisioning services are based on a STAC API data catalogue based on stac-fastapi-pgstac together with a STAC Browser for interactive exploration of the catalogue. OGC services for data access and visualization as well as a resource catalogue for algorithms, Jupyter Notebooks, workflows, etc. are both on the roadmap.
A terrabyte application hub based on Open OnDemand is available to launch interactive applications on the terrabyte HPC system. Applications, such as JupyterLab, QGIS, R-Studio, and Visual Studio Code, are available to be launched with user-defined computing resources (e.g., number of CPUs, GPUs, and RAM). Data processing services include data cube analyses based on Open Data Cube, xarray, and Dask and container-based processing. Services, such as openEO API and OGC API Processes for EO Application Packages, are currently in development.