Monitoring cluster resources
Monitor all resources
The availability of cluster resources is of great interest for all users. While sinfo and scontrol are powerful built-in tools to monitor SLURM and cluster resources, they are not that handy to work with. We provide a tool called check_cluster that wraps around scontrol and nicely visualizes the most important information on the command line:
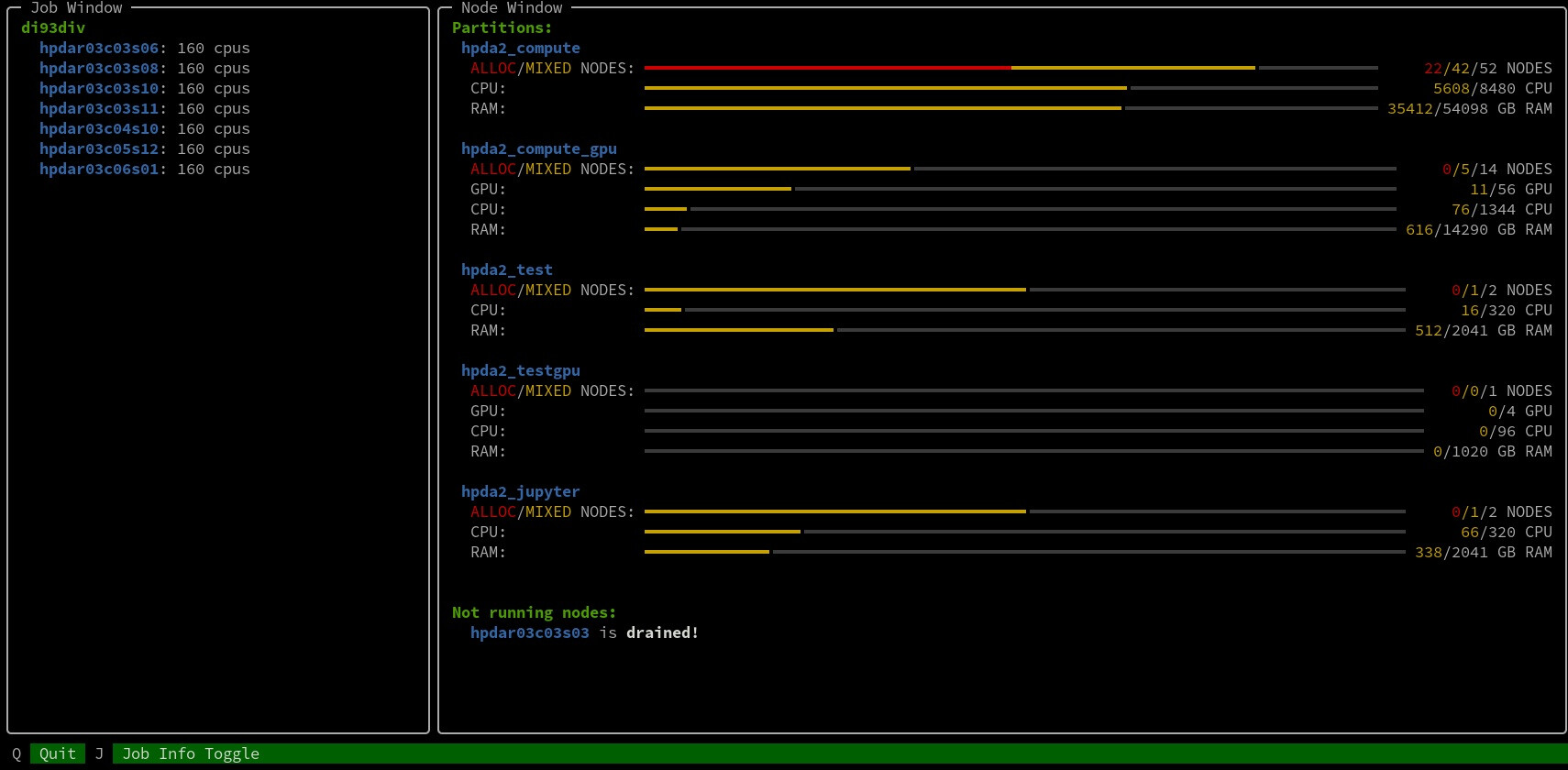
The tool can be easily loaded from our terrabyte modules:
module use /dss/dsstbyfs01/pn56su/pn56su-dss-0020/usr/share/modules/files/
module load check_cluster
check_cluster
Monitor GPU usage
Nvidia-smi is a well known standard-tool for monitoring GPU-resources on a single-node-level and is available on all of our GPU-nodes.
Nevertheless, we encourage you to try cluster-smi, which is the same as nvidia-smi but for multiple nodes. This is advantageous especially for jobs that run on multiple GPUs in parallel.
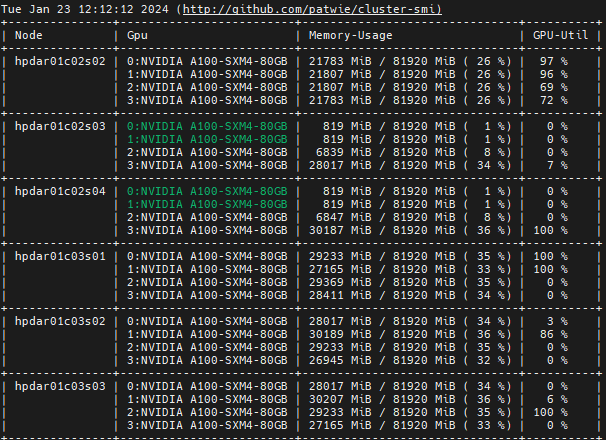
You can simply use it by running cluster-smi on the login node. You then should see the usage information of all available nodes:
cluster-smi
In order to filter for jobs running under your user name, you can use the -u flag + your terrabyte-ID:
cluster-smi -u <your ID>
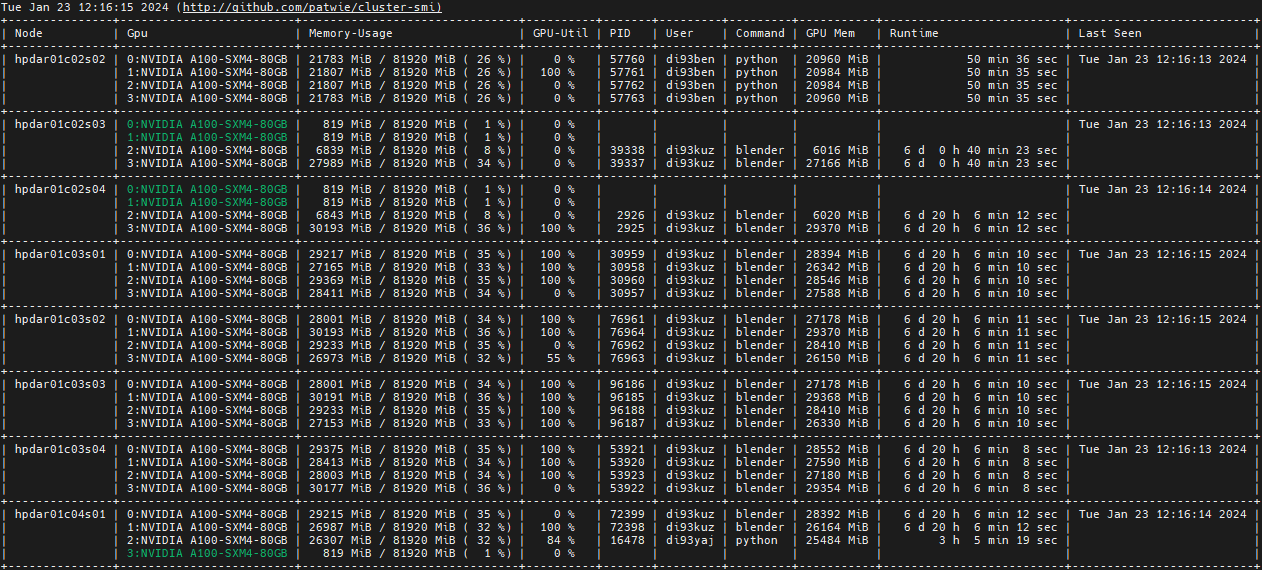
In order to get more detailed information, as well as a time stamp of the measurement, you may use the -p and -t flags:
cluster-smi -p -t
You can use the -n flag to filter all nodes and only show those matching the given regEx:
cluster-smi -n hpdar01c05s02
